
Data Formats and Encoding
A peek into different formats used for data transmission

In applications, there are multiple occasions for data to be transmitted.
But applications need data in their native format. Programming languages store data in the form of internal representations like hash tables, linked lists inside the memory, optimized for their use case. For long-term use, they can also store data in formats that only they can decode. For e.g. Python can store data in pickle files.
While this works for their internal use case, if they have to transmit data over the network, this format has to be converted to byte sequence and transmitted. The application that is receiving this should be able to parse this byte sequence and convert it back to a data format that makes sense to it.
Usually, these transmissions may not be between applications that understand each other’s data formats. For e.g. consider a ReactJS app sending some data over the network to a Django backend application. The representation of arrays in React won’t be similar to lists in Django. Hence, you need to have consistent formats for transmitting data.
JSON & XML
These are the most popular ones. Most people who have worked with APIs might have used one of these formats.
While JSON is the more popular one, XML is also used in many places.

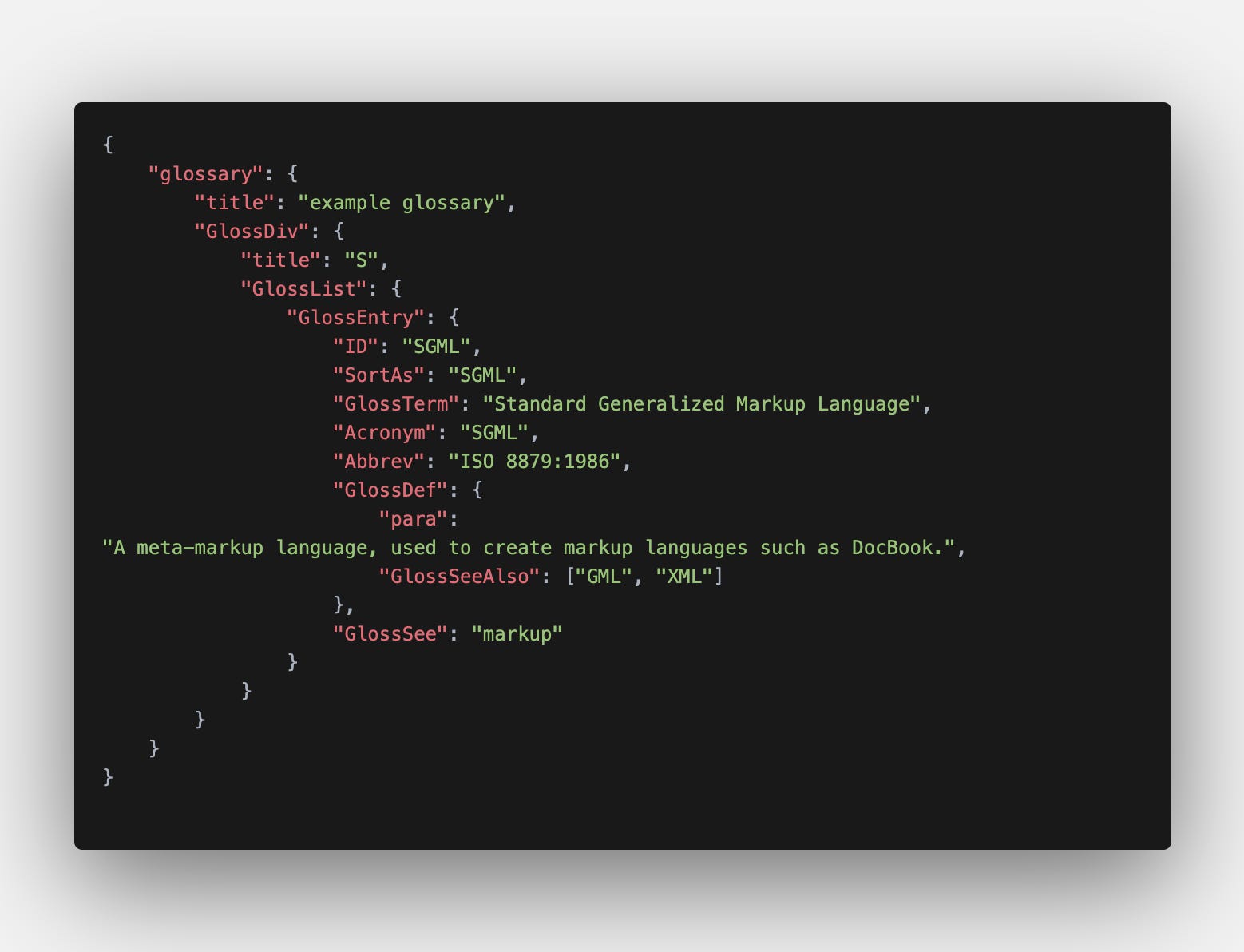
JSON supports various types of data, such as strings, numbers, boolean, arrays, etc. but it doesn’t have strict type checking.
XML and JSON have optional schema support. i.e. if you wish to add a schema to it so that data transmission becomes consistent, then you can. Since it’s not strict, you won’t usually find schema definitions for them.
JSON is more readable as compared to XML since XML has enclosing tags which makes it less pleasing to the eyes. Basically, these formats are popular mostly because they are readable. There aren’t a lot of added advantages otherwise. These are called self-describing data formats for a reason. In fact, JSON only supports numbers in a general way, there’s no difference between a floating-point number and an integer.
Another issue associated with such formats is the amount of space they consume. There are a lot of unwanted characters, repeating tag names, etc. in the data which takes up space, like curly braces in JSON and start and end tags in XML. This doesn’t matter much when the amount of data is small. But it starts cascading when there are too many records.
Binary encoded JSON & XML: JSON and XML formats consume a lot of space. The individual characters in these formats can be encoded using their ASCII equivalent code and replacing delimiters like curly braces and commas using sequence length representations.
For e.g. a word like user can be replaced using the ASCII equivalent of u, s, e, and r with 75, 73, 65, and 72.
I can also represent the length of the string as 4, so I don’t have to include the delimiters to mark the end of a sequence. The program will know to stop processing after 4 characters.
Avro and Protobuf
As mentioned above, JSON and XML are not efficient in storing data. Other data formats had to come up to replace them. Even the binary versions of them are only partially optimised.
Avro is an Apache open-source data serialization system.
Protobuf is short for protocol buffers and is developed by Google for data serialization purposes just like Avro.
These formats use explicitly defined schema which the writer and the reader of the data have to follow while encoding or decoding (serializing or deserializing) the data.
Both of them are binary data encodings which save a lot of space as compared to JSON and XML formats.
One of the ways Protobuf saves space is by avoiding explicit tags, such as glossary in the above JSON example. They associate a number for each tag defined in the schema. And the number is used everywhere to refer to this tag. Hence, when you are changing the name of the tag, you don’t have to go through the entire data and update its occurrences. You just have to change it in one place.
Data science enthusiasts may find a lot of datasets available in protobuf formats. As compared to other forms in which the data is available (like CSV), protobuf format files are much smaller in size.
Avro uses the tag names directly as opposed to tag numbers like in Protobuf. The data type of the tag value is defined in the schema, but in the case of Protobuf it is defined inside the data itself. Comparatively, Avro consumes lesser space than Protobuf.
Avro stores the schema along with the data. While reading Avro encoded data, you will have to go through the schema and parse the data according to the schema. So if you have an older version of the schema, then you may not be able to parse the data properly.
Avro also resolves schema differences for the application reading the data. For e.g. if the order of fields is different for both the program reading the schema and the schema which is stored with the data, then Avro figures out which fields are equivalent.
📖 Read recommendations for the week
If you like my content and want to support me to keep me going, consider buying me a coffee ☕️ ☕️
Connect with me!
If you need help with your service architecture, you can email me 💌 : dennysam14@gmail.com