

How to avoid Single Point of Failures in your service?
How to avoid Single Point of Failures in your service?
Planning your infrastructure for high availability can lead to happier customers

Hello reader, hope you had a great week. Before we get into the 2nd week of the year, let us push yourselves to think a bit about the architecture of your application, and how careful planning can avoid failure of your service.

On July 2020, services like Shopify, Discord and Feedly among others were severely affected due to an outage in CloudFlare’s network. CloudFlare started their own DNS service called 1.1.1.1, which, they claim, speeds up DNS lookups. This DNS service had an outage when one of their routers in Atlanta started announcing bad routes. Here’s what the CEO of CloudFlare has to say.

This is a classic example of how your service can go down when it’s dependent on a single entity’s availability. Companies dependent on CloudFlare were unserviceable. We outsource much of our infrastructure to other companies because, let’s face it, maintaining and running an infrastructure is hard. Creating a CDN network or setting up our own servers is not easy.
What is Single Point of Failure?
A single point of failure (SPOF) is when the failure of a single entity in your service can cause the entire service to go down. It can be a software or a hardware entity.
First things first, fault in a system is not something you can avoid completely. Be it hardware or software, faults tend to happen. It can be due to a buggy hardware component, like a router, or a bug in the code. But these faults shouldn’t lead to the failure of the entire system.
💡Did you know?
A Fault is when a single unit fails to do its job. A Failure is when a fault causes an entire system or service to go down.
While faults are imminent, failures are something we should strive to avoid.
How to avoid SPOF?
In the software world, we stress a lot on avoiding redundancy. Redundancy in codebases can lead to lowering the maintainability of code. But when it comes to hardware infrastructure, redundancy is the norm. Because unlike software, if one node fails, the other can take over.
Let’s see an example infrastructure and various single point of failure in it.
A Basic Architecture
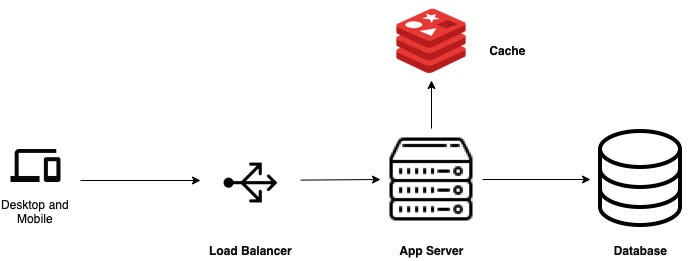
When you start building your application, the infrastructure may look something like the above.
The client will make a request to the load balancer, the load balancer will point it to the app server. The app server fetches data either from the cache or from the database and returns a response. Sounds cool and simple! But what if the cache server crashes? You can get the data from the database. But what if the database crashes? You service will be down until you recover the DB. And what if the app server crashes? You get my point!
Oh btw, the load balancer is not really required if you have only one app server. 😉
To avoid this, you will have to add spares for these components. These spares act like a spare tire in your car. When one of the components go down, the spare one takes over. This is the redundancy I was talking about.
The spares can also be of various types. Namely, active and passive.
Active components are the ones which are always working, helping distribute the load.
Passive components stay idle but takes over the job of the primary components only when the primaries fail.
🧠 Keep in mind that active spares are required if your service needs minimum downtime, but it can double the costs. Also, if you don’t have a huge user-base, most of the hardware resources go under utilised here.
Let’s see what it will look like when we add some spares to the above system.
A slightly advanced architecture

I have added an extra app server. The load balancer uses a round robin approach to decide which app server to route the traffic. In case one of the servers is down, the other one will serve all the requests.
The app servers are directly connected to the primary database. I have added a secondary database which will act as a passive spare. All the transactions are handled by the primary database. The primary database is responsible for syncing the data with the secondary database. Whenever the primary goes down, the secondary database can take over and handle the transactions. For this to work reliably, the primary and secondary databases should always be in sync.
For brevity, I haven’t added redundancy for load balancers, although it’s possible that your load balancer can also go down. In that case, none of the traffic which is coming to your service will be routed to the app servers.
Redundancy across regions
So far we have tried to avoid SPOF for individual components. But what if the datacenter in which all these servers reside goes down due to power failure or some other cause? 🤔
All these redundancies won’t help at that point. So it is ideal to have these redundancies in separate regions rather than having them all in one region.
For e.g., you can create your primary database in one region (Asia) and your secondary database in another region (Europe).
But this comes with a caveat. When your databases are in different regions, the time taken to sync data between both will increase since the distance between the machines have increased. This has to be kept in mind while designing your architecture.
But thankfully, many of these decisions will already be made for you if you are using a cloud service provider like GCP or AWS. For e.g. in GCP, while creating a database for your service, you can opt for High Availability, which will automatically create a synced DB in another region for you. Same is the case with app servers. You can create a Managed Instance Group which will automatically allot a minimum number of servers for your service and if one goes down, it will create another for you.
Fault detection & Recovery
Redundancy is cool, but if something fails, you need to be notified about it so that you can act upon it. So failure detection and recovery are the other two things you should invest in.
For fault detection, you can create health checks. There are various freely available services you can employ for it. GCP has its own Uptime Checks for the purpose.
Once the issue is detected, recovery processes should get triggered and components which are down should be brought up. This is supposed to be an automatic process. But in certain scenarios manual intervention may also be required
Availability & SLAs
Let’s talk a bit about SLAs. SLAs or Service Level Agreement is a policy created by the service for their consumers ensuring them a certain amount of availability of the service, say 99.9%. Usually this is generated for paying customers where they can claim for a refund if the service doesn’t meet the minimum availability promised.
For e.g. Amazon promises availability above 95% for their compute services, failing which you can avail a 100% service credit. Here’s a breakdown of their region level SLA:

Source: https://aws.amazon.com/compute/sla/
Through this, what Amazon is promising is that their services will be available even if certain nodes may go down or are unavailable. Similarly, your customers will have certain availability expectations regarding your service. And as a service, it’s your responsibility to meet these expectations. When you create an infrastructure with SPOFs, you are making it more likely to have more downtime leading to frustrated customers.
Your infrastructure should be such that when faults happen in a component, other components should be able to take the load till the recovery is completed.
Wrapping up
In this issue, I have only scratched the surface of what all can go wrong when you have an infrastructure unplanned for downtime. My intention is to help you think deeper when you design your system architecture. If you are using a managed service like AWS or GCP, you are still not in safe hands.
There was this one instance, where our AWS EC2 server went down and one of our apps had a few hours of downtime because we didn’t add a spare back then. So gambling on your system wouldn’t be a wise thing to do if you care about your customers.
You can follow me on Twitter, where I share tweets about Software Architecture, Startup Ecosystem, and books.
If you need help with your service architecture, you can also email me 💌 : dennysam14@gmail.com
very informative.